
Connections
Connections? and Edges? and Nodes? Oh my?!?!
The concept of “edges” and “nodes” in GraphQL Schemas can be confusing at first. Below is a brief overview of these concepts, and following is a more detailed history and explanation of their history and implementation in WPGraphQL.
A Brief Overview of the Concepts of Connections
Below is an image that attempts to visualize what an “application data graph” might look like.
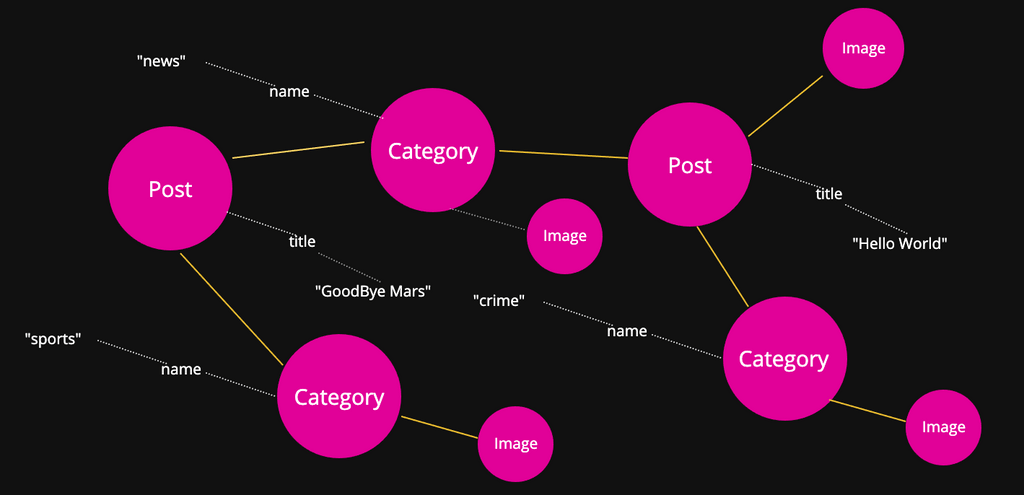
In the image, the pink circles represent individual resources, or “nodes”. The “nodes” have individual properties as well as connections to other resources. For example, a Post in WordPress can have properties such as Title, and can be connected to other “nodes” such as Images and Categories. The Image and Category nodes can have their own properties such as “name” and “sourceUrl”, and can also have “connections” to other nodes. The yellow lines between the “nodes” represent the “edge” of the connection where contextual data can be represented.
To help understand “edges”, consider a Social Network, where there might be two Users that are friends. The date the two users became friends is not a property of either user, but a contextual property about their connection as friends. That contextual data that exists only in the context of a connection between nodes is considered “edge” data.
To summarize:
- node: A node is an individual resource. For example, a Post, Page or User.
- nodes: A collection of one or more resources
- edge: The space between connected nodes where contextual data can be accessed.
- edges: A collection of one or more edges
Relay Specification
WPGraphQL follows the Relay Specification for GraphQL Schema Design.
You can read more about the official Relay Spec on their site. Below you can learn about some of the reasons WPGraphQL is designed following the Relay Spec.
Some history
Very early on in the development of WPGraphQL, posts were exposed as a listOf => 'Post'. That meant that a list of posts could be queried like so:
{
posts {
id
title
date
}
}
And a response would look something like:
{
"data": {
"posts": [
{
"id": 1,
"title": "Hello World"
},
{
"id": 2,
"title": "Hello World, again"
}
]
}
}
Problem: Pagination
This worked well, if the only goal was to get a small set of data. But, for WordPress sites with more than a few posts, this doesn’t scale, because there was no good way to handle pagination. To paginate, the UI needs more information from the server to determine if there are more items to fetch, how to fetch them, etc.
An early iteration of the WPGraphQL Schema adjusted to allow querying posts like so:
{
posts {
pageNumber
nextPageNumber
postsPerPage
items {
id
title
}
}
}
By nesting the posts a level deeper, the client could ask for the items, but also ask for data related to pagination, such as the pageNumber, nextPageNumber and postsPerPage. With that info, the client could make another request to get the next page of data.
The follow-up request would have looked something like:
{
posts(postsPerPage: 5, page: 2) {
...PostsFields
}
}
This worked ok, so we could implement it for other Types, right?
Well, this just looked weird:
{
tags(postsPerPage: 5, page: 2) {
...TagsFields
}
}
Problem: Naming Conventions
The name postsPerPage seemed only applicable to Posts. We’d need different terminology for paging Terms.
We could match WordPress internals and use posts_per_page and paged for Post objects, and number / offset for Terms, and Users. But this seemed a bit tacky. There was an opportunity to abstract things to paginate using the same terminology regardless of what Type is being paginated, including Types, such as Themes and Plugins that have no way to be paginated in WordPress currently.
Surely there was a way we could paginate all types of data with the same conventions!
Problem: Contextual Relationship Data
WordPress core doesn’t store much contextual data in regards to relationships between 2 objects. But many plugins and themes do.
One example of contextual data I’ve experienced in WordPress is “Custom Captions”.
The idea is that when a media item is used from the media library, the post it’s being used on could set a “custom caption” that users would see when that image was displayed on that Post. But if the image were displayed on another Post, that post could also set a “custom caption”.
So, we might have one Image connected to two or more Posts, and a different caption for each connection between the Image and Post.
We needed a way to expose this contextual data in a way that a caching client could make use of.
If we were to expose this caption as a property of the Image, this would cause problems with any caching client.
A caching client will cache the Image based on its ID, and will cache fields against that ID. If the caption field were “Custom Caption 1” when queried in connection to Post 1, and “Custom Caption 2” when queried in connection to Post 2, then whichever “connection” was queried last would write to the cache last and we’d have a bug where the contextual caption wouldn’t be displayed properly.
Relay Spec for Connections
While researching various ways to paginate, The Relay Specification was discovered, and it aimed to solve many of the issues we had experienced.
Relay introduces the concept of “Connections”. You can read about them in the official Relay Connection Specification.
Connections aim to solve, or at least ease, the pain points in the issues discussed above.
Solution for Pagination
Relay solves the problem of pagination by exposing pageInfo fields when querying for collections of items. This enables clients to query enough information to know if there are more items to be queried and how to query the next set of items in the collection.
In WPGraphQL, when querying for posts, we can query pageInfo like so:
{
posts {
pageInfo {
hasNextPage
endCursor
}
edges {
cursor
nodes {
id
title
}
}
}
}
In this case, the field pageInfo.hasNextPage will return true or false providing the client enough information to know if there is another page of Posts. If hasNextPage is true, the client may want to request additional resources.
A follow up request could be made, by passing the endCursor to the next query as the value of the “after” argument, like so:
{
posts(first: 5, after: "endCursorFromPreviousRequestGoesHere") {
pageInfo {
hasNextPage
endCursor
}
edges {
cursor
nodes {
id
title
}
}
}
}
The above example demonstrates how a Schema designed following the Relay Specification addresses the “pagination” problem.
If we look closely, we can also see that this addresses the other problems.
Naming Conventions
It provides agnostic, consistently named fields for paginating any type of Data. We can now use the same pageInfo fields (hasNextPage, endCursor) and the same arguments (first, after) for pagination of Posts, Pages, Tags, Categories, Users, Comments, and even data that’s not traditionally easy to paginate in WordPress, such as Themes and Plugins!
Contextual (edge) Data
Because the shape of the queries consist of edges and nodes, we can query contextual data that is not a property of the node (resource) itself, but just contextual to the connection it belongs to.
In the above examples, the field cursor is selected on the edges. The cursor is a contextual pointer to where in the specific connection a node exists. It’s not a property of the node itself, but a property of the node within the specific connection being queried.
Connections? and Edges? and Nodes? Yes Please!!!!
We hope the above explanations clarify why WPGraphQL is built with the Relay specification in mind. Now, go forth and GraphQL!